

 个人中心
个人中心
 我是园区
我是园区
 退出
退出
您还不是认证园区!
赶快前去认证园区吧!

一直以来,游戏都是验证 AI 功能的主要方式。为此,科学家不断寻找能够对 AI 科学问题进行模拟与测试的游戏。最终,国际象 棋成为 AI 的试验场。
2017 年,DeepMind 推出了针对棋类游戏的强化学习算法 AlphaZero。它可以在没有人类监督的情况下,自动地从对弈数据中不断总结经验、从零开始学习最优的下棋策略,最终探索和设计出新的国际象棋套路。
最近,DeepMind 与谷歌大脑(Google Brain)团队合作开展了一项研究,回顾了国际象棋作为人工智能试验场的作用,并证明了 AlphaZero 网络模型能够学习国际象棋知识。
概括地讲,此项研究的创新点在于提升了研究者对以下几个方面的理解:模型对人类国际象棋知识概念的编码、模型在训练过程中对知识的获取、利用编码后的象棋概念对价值函数的新诠释、AlphaZero 的进化与人类棋手行为之间的比较、AlphaZero 对象棋走法倾向的演变、以及对无监督概念学习的原理性验证。
近日,相关论文以《AlphaZero 对国际象棋知识的获取》(Acquisition of Chess Knowledge in AlphaZero)为题,发表在 PNAS 上[1]。

为深入探究 AlphaZero 学习并获取人类国际象棋概念知识的过程,研究者采用了三种方法。
 AlphaZero 网络模型模仿人类下象棋
AlphaZero 网络模型模仿人类下象棋
根据论文内容,AlphaZero 网络模型由残差网络(ResNet)和蒙特卡洛搜索树(Monte Carlo Tree Search,MCTS)构成,能够不断学习并模仿人类下棋。
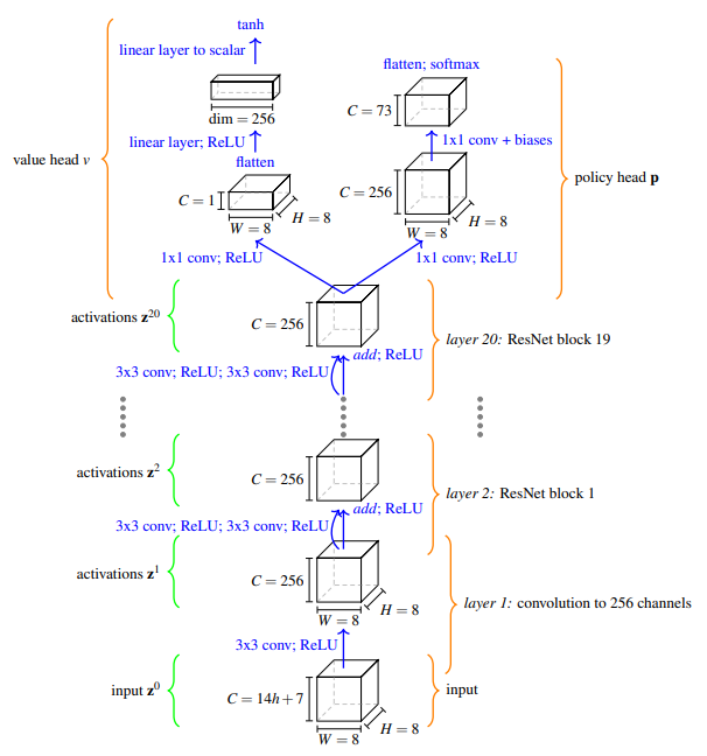
首先,AlphaZero 网络模型的输入为实值 向量 z 0 ,该向量是表示象棋的排布方式的函数。z0 中的前 12 个尺寸为 8×8 的通道是二值的,分别编码了玩家和对手的王、后、车、象、马和兵的位置(共 6 类棋子,每类棋子双方各占 1 个通道,共计 12 个通道)。
后面是 2 个 8×8 的二值通道,表示局面重复次数(采用三次局面重复和棋制);1 个通道用来表示当前是我方还是对方回合;再加上 4 个通道用来统计双方能否短易位或者长易位;最后 2 个通道是棋子不可逆移动次数计数器 (适用于 50 步限着规则) 和棋子总移动次数计数器。
输出函数 p,v =f θ (z 0 )是模型的输出,从训练数据中学习从而能够预测到的两个量:即从当前棋盘状态预测对弈的预期结果 v,以及下一步各个棋子移动的概率分布 p。这两个量都能够在 MCTS 中被搜索到,并被称为“价值头”和“策略头”。
总之,AlphaZero 模型能够利用反复自我对弈时产生的数据,并不断训练学习,进而生成新的、更强的模型。

验证 AlphaZero 模型的可行性
接下来,研究者采用“稀疏线性探测法”确定 AlphaZero 网络能够展现人类象棋观念的程度与范围。不仅如此,他们还寻找出该探测方法的局限性,并探索了未来的研究方向。
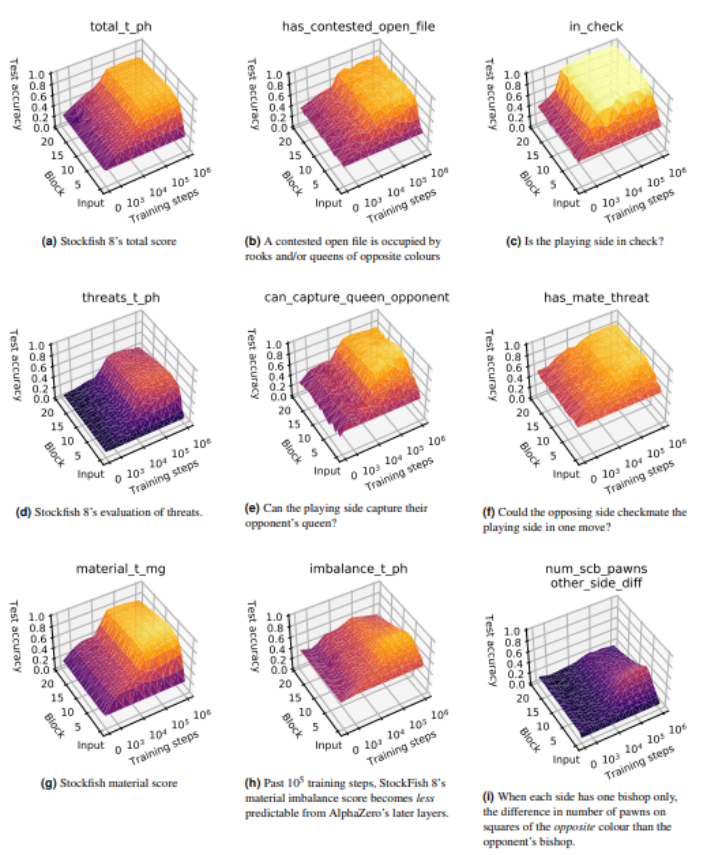
为验证 AlphaZero 的性能,研究团队还抽取十万盘游戏对 AlphaZero 的下棋水平进行测试。结果表明,当下棋的步数与神经网络模型中的模块数增加时,AlphaZero 获得的分数也在逐渐上升。
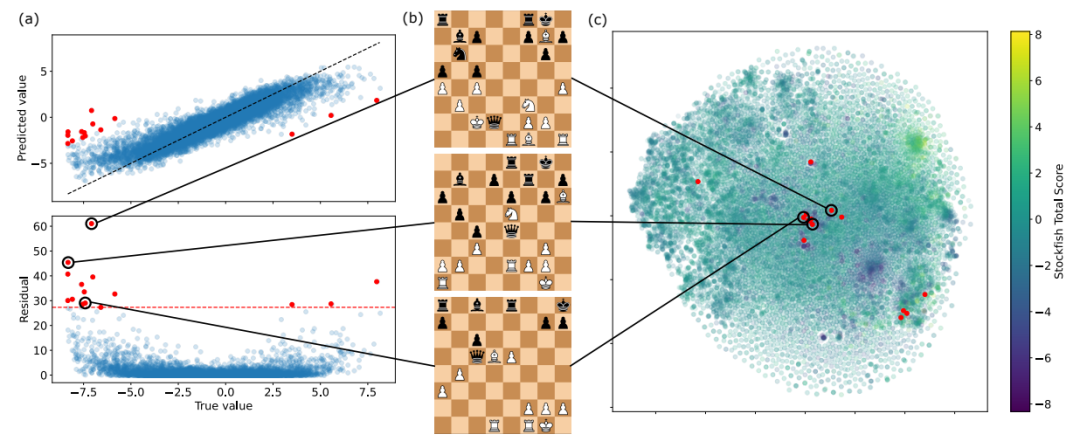
由于实验中出现了残差(实际观察值与估计值之间的差),研究者根据散点的分布分析残差出现的原因和具体位置。
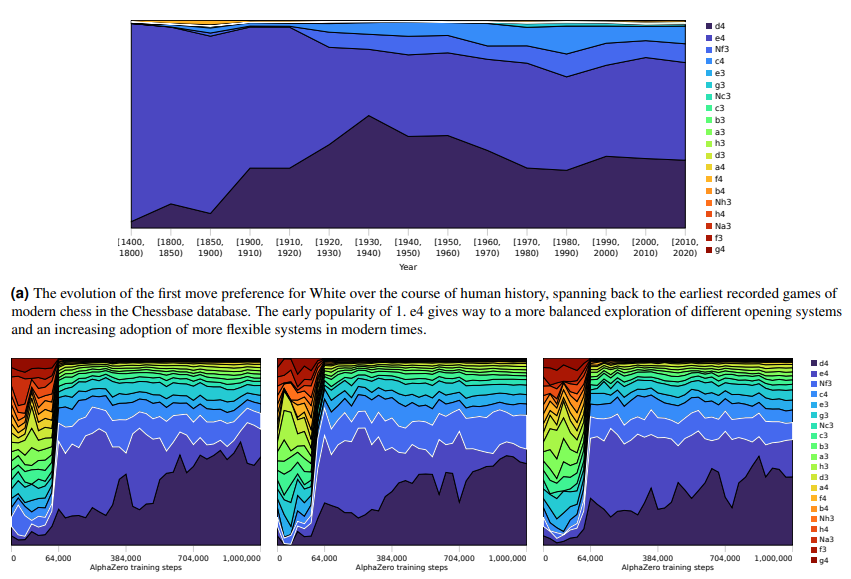
最后,研究者对比分析了 AlphaZero 下国际象棋和人类下棋模式的演变与进展。结果表明,随着时间推移,AlphaZero 下棋路径选择范围在缩小,而人类下棋路数随着历史逐渐增加。
总地来说,该论文详细描述了 AlphaZero 神经网络从最初开始训练下棋到训练结束的全部流程。

支持:王贝贝
1.Thomas McGrath,Andrei Kapishnikov,Nenad Tomašev,Adam Pearce,Demis Hassabis,Been Kim,Ulrich Paquet,Vladimir Kramnik.PNAS.(2022) https://www.pnas.org/doi/10.1073/pnas.2206625119
https://twitter.com/weballergy/status/1461281358324588544








