

 个人中心
个人中心
 我是园区
我是园区
 退出
退出
您还不是认证园区!
赶快前去认证园区吧!

当前,多模态学习成为 AI 的热门技术趋势之一,尤其是在文本生成图像的应用方面。前不久,OpenAI 开发了升级版的 DALL-E 2,不仅可以将文字转换成具有高分辨率与低延迟的真实图像,还能对所生成的图像进行二次的编辑。
近日,谷歌研究(Google Research)推出了一个具有类似功能的图像生成器“Imagen”,其能够根据输入的文字描述生成油画、照片、绘制和 CGI 渲染图像。值得一提的是,相比 OpenAI 的 DALL-E 2,Imagen 所带来的图像真实感更强,对于语言理解的准确度也更高。 图 | Imagen 生成的一个图像(来源:Google Research)
图 | Imagen 生成的一个图像(来源:Google Research)
据了解,谷歌通过引入测试基准 DrawBench,对 Imagen、DALL-E 2、VQ-GAN+CLIP和 LDM(Latent Diffusion Models)几类模型进行了深入地评估与对比。结果得出,无论是在样本质量还是图文对齐方面,Imagen 的评分都位居第一。
图 | DrawBench 对 Imagen、DALL-E 2、VQ-GAN 和 LDM 的测试结果(来源:Google Research)
例如,DALL-E 2 在面对一些同时出现两个颜色的文本时表现不佳,而 Imagen 可以很好地应对这些情况。此外,当文本中出现有位置和效果指向的具体字样时,Imagen 也比 DALL-E 2 的表现更好。

图 | 面对同时出现两个颜色的文本,Imagen 和 DALL-E 2 生成的图像对比(来源:Google Research)
不过,在反常识文本的情况下,目前 Imagen 和 DALL-E 2 都未能准确地理解并输出对应的图像。
图 | Imagen 和 DALL-E 2 对“马骑着宇航员”文本分别生成的图像(来源:Google Research)
那么,Imagen 具体是如何工作的呢?据介绍,“Imagen 主要依赖的是大型 transformer 语言模型在理解文本方面的强大能力和扩散模型在高保真图像生成方面的优势。”
在用户输入文本后,Imagen 首先使用 T5-XXL 编码器训练并嵌入文本,然后通过一系列扩散模型,将文本映射到 64×64 像素的低分辨率图像中,再采用文本条件超分辨率扩散模型对图像进行 2 次升采样,最终将图像升级为 1024 x 1024 像素的高分辨率图像。
另外,相比以往出现的图像生成器,谷歌在 Imagen 中做了一项重要的改变,使其工作效率和质量得到了进一步提升。此前,图像生成器多是通过 CLIP 来把文本映射图像中,再指导一个生成对抗网络 (Generative Adversarial Network, GAN) 或者扩散模型来输出最终的图像;而在 Imagen 中,文本编码的训练任务仅由纯语言模型来完成,文本映射图像的生成任务则全部交给了图像生成模型。
文本理解方面,CLIP 的图文对训练集是有限的,而 T5-XXL 编码器含有 800GB 的纯文本语料训练库,比 CLIP 要全面得多。在保真度和语义对齐上,T5-XXL 编码器的能力也更强。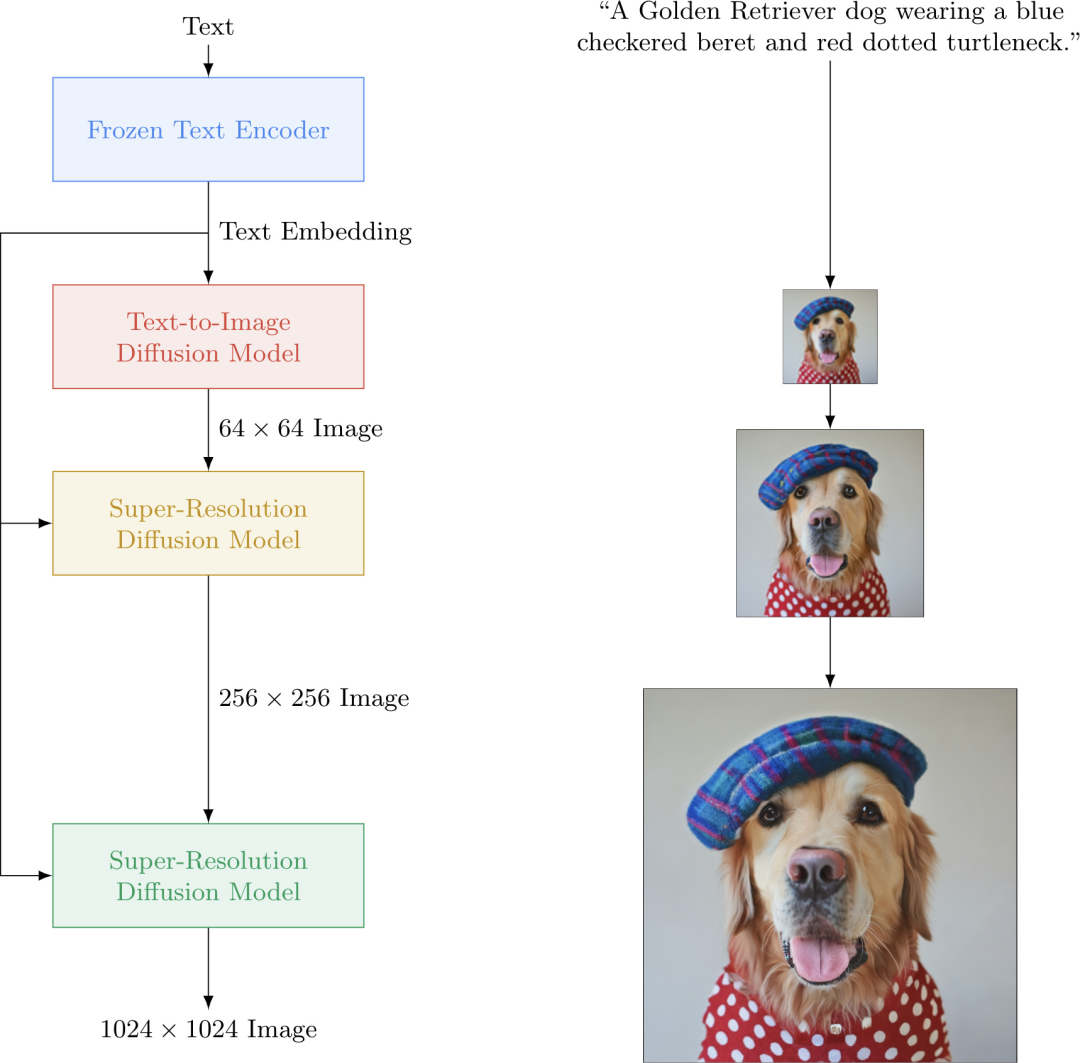 图 | Imagen 的可视化工作流程(来源:Google Research)
图 | Imagen 的可视化工作流程(来源:Google Research)
研究中,谷歌还发现,“在 Imagen 中,语言理解模型的规模大小对图像效果的积极影响胜于图像生成模型,增加语言模型的大小可以大大地提高样本保真度和图文对齐度。”
除此之外,谷歌对 Imagen 的扩散模型进行了优化,其通过在阈值扩散采样器增加无分类器引导(classifier-free guidance)的权重提升输出图像的图文对齐度,又增多了低分辨率图像的噪声以解决扩散模型的多样性不足,还引入新的 Efficient U-Net 架构带来了更优的内存效率、收敛速度及计算效率。
完成以上改进的 Imagen 模型在未用流行目标检测数据集 COCO 训练过的情况下,在其测试中拿到 7.27 的 FID 高分。并且,其样本质量在图文对齐上与 COCO 训练集的参考数据不相上下。与此同时,Imagen 也在 COCO 测试中暴露出在人物类图像表现不佳的缺陷。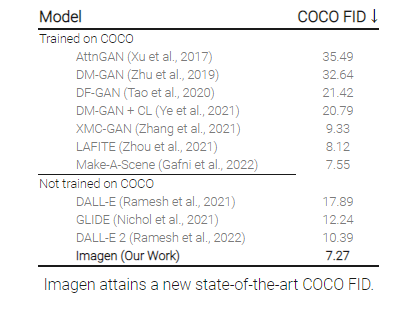
图 | Imagen 在 COCO 测试中的数据表现(来源:Google Research)
需要注意的是,目前文本到图像的研究仍存在伦理方面的问题。对此,谷歌进行了相关总结,并提出一些针对 Imagen 在这方面的举措。
一方面,文本生成图像的应用范围极其广泛,对社会有潜在的滥用风险。所以,谷歌不计划公开 Imagen 模型的代码及演示,而且他们将开发一个负责任的外部化框架来避免各类该模型可能带来的风险。
另一方面,文本生成图像的训练需在网络上抓取大量数据集,包含色情图像、社会刻板印象以及压迫性观点等不良内容。Imagen 所依赖的文本编码器也是在这类数据集上训练的,在语言理解上具有偏见和局限性。因此,谷歌决定,在未得出进一步保护措施前他们不会开放 Imagen 供公众使用。
未来,他们将在社会偏见的审计和评估方面做更多的工作,围绕一系列社会和文化偏见的数据集展开更深入地实证分析,以改善 Imagen 在输出人物类图像时的局限性。
-End-

参考:
https://gweb-research-imagen.appspot.com/paper.pdf
https://arxiv.org/abs/2205.11487
https://imagen.research.google/
https://www.republicworld.com/technology-news/other-tech-news/google-develops-ai-text-to-image-generator-offering-unprecedented-degree-of-photorealism-articleshow.html








