机器之心 & ArXiv Weekly Radiostation
本周的重要论文包括MIT等研究者通过观测引力波首次证实了霍金面积定理;来自新加坡 Sea 集团旗下、颜水成教授领导的 Sea AI Lab (SAIL) 团队提出的一种新的深度学习网络模型结构——Vision Outlooker (VOLO),用于高性能视觉识别任务等。
Testing the black-hole area law with GW150914
VOLO: Vision Outlooker for Visual Recognition
Strong quantum computational advantage using a superconducting quantum processor
Deep Learning for AI
Scaling Vision Transformers
CoAtNet: Marrying Convolution and Attention for All Data Sizes
Early Convolutions Help Transformers See Better
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:Testing the black-hole area law with GW150914
摘要:
1971 年,霍金提出了面积定理(area theorem),引发了人们对黑洞力学的一系列基本见解。该定理预言,黑洞视界的总面积不会减小。与热力学第二定律惊人地相似,该定律指出:熵,或物体内的无序程度,也永远不应该减少。这一定理也被称为黑洞物理学第二定律,也是霍金最著名的定理之一。
该定理已经在数学上得到了证明,但从未在自然界观测证实。
50 年后,来自 MIT、石溪大学、康奈尔大学以及加州理工学院等机构的研究者通过观测引力波首次证实了霍金的这一定理,其研究成果于今年 5 月被《物理评论快报》接收,于近日被接收。
研究者对 GW150914 进行了仔细的观察,它是由位于美国的激光干涉引力波天文台(LIGO)于 2015 年 9 月 14 日探测到的引力波现象,是人类首次直接探测到的引力波。这束产生于双黑洞的引力波信号与广义相对论中对双黑洞旋近、并合以及并合后的黑洞会发生衰荡(ringdown)的理论预测相符。
简言之,这一引力波信号是生成新黑洞的两个旋近黑洞的产物,伴随而生的巨大能量以引力波的形式在时空中波动。如果霍金的面积定理成立,则新黑洞的视界面积不应小于母黑洞的视界总面积。
研究者重新分析了宇宙碰撞前后 GW150914 的信号,发现合并(merger)后视界总面积的确没有减少,他们得出了 95% 的置信度结果。
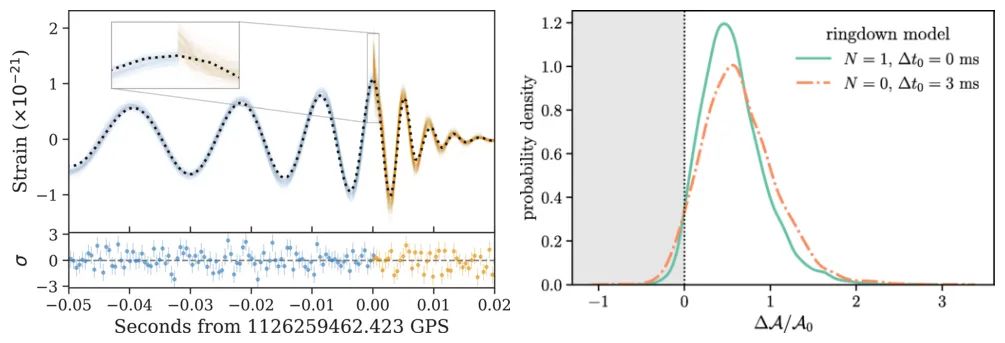
图左为 GW150914 的重建,图右为 GW150914 合并前后视界面积的分值变化。
推荐:
时隔 50 年后,MIT 等首次证实霍金面积定理,黑洞总视界面积达 36.7 万 km²。
论文 2:VOLO: Vision Outlooker for Visual Recognition
摘要:
在一篇最近发表的论文中,来自新加坡 Sea 集团旗下、颜水成教授领导的 Sea AI Lab (SAIL) 团队提出了一种新的深度学习网络模型结构——Vision Outlooker (VOLO),用于高性能视觉识别任务。它是一个简单且通用的结构,在不使用任何额外数据的情况下,实现了在 ImageNet 上图像分类任务 87.1% 的精度目标;同时,实现了在分割数据集 CityScapes Validation 上 84.3% 的性能,创下 ImageNet-1K 分类任务和 CityScapes 分割任务的两项新纪录。
VOLO 框架分为两个阶段,或者说由两个大的 block 构成:
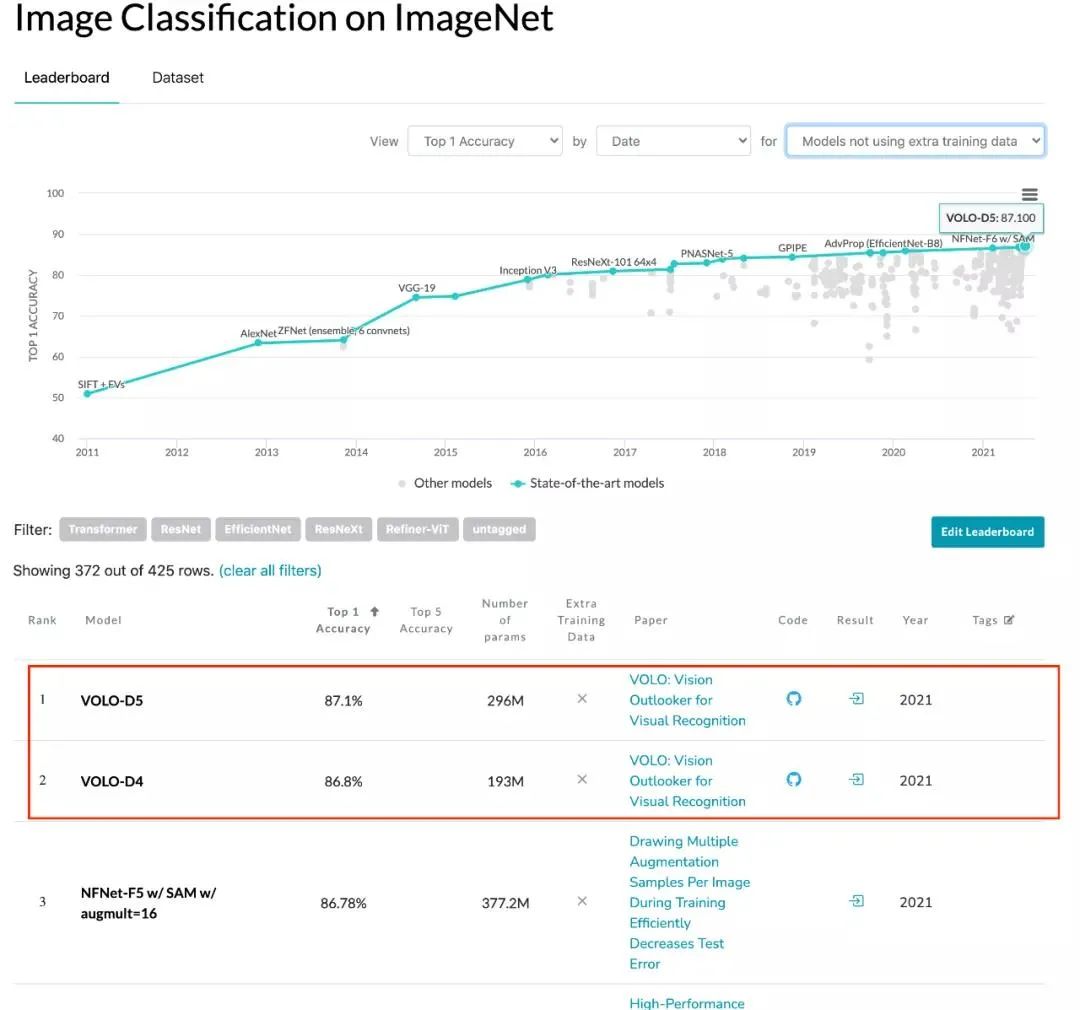
ImageNet 分类性能实时排行榜(无额外数据集),来源 https://paperswithcode.com/
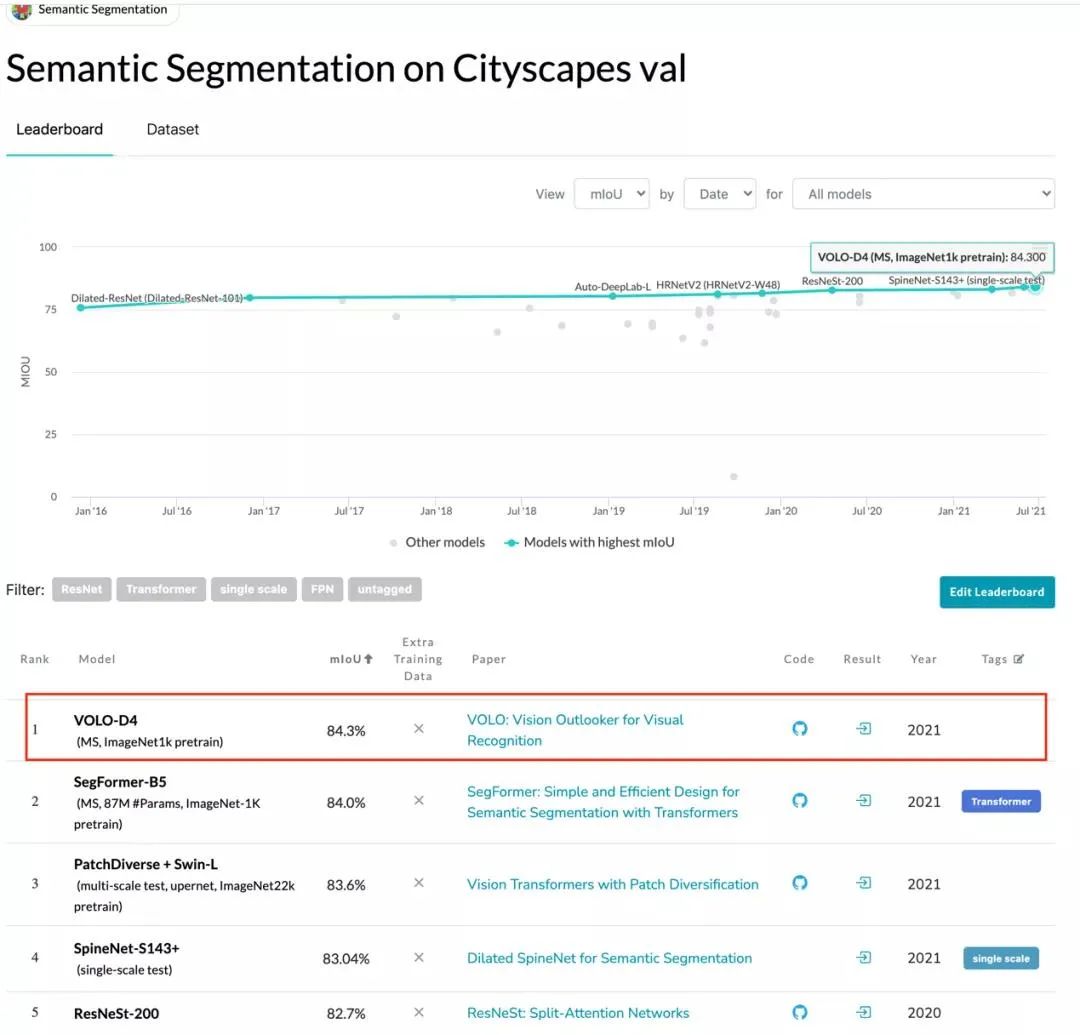
Cityscapes validation 实时排行榜,来源 https://paperswithcode.com/
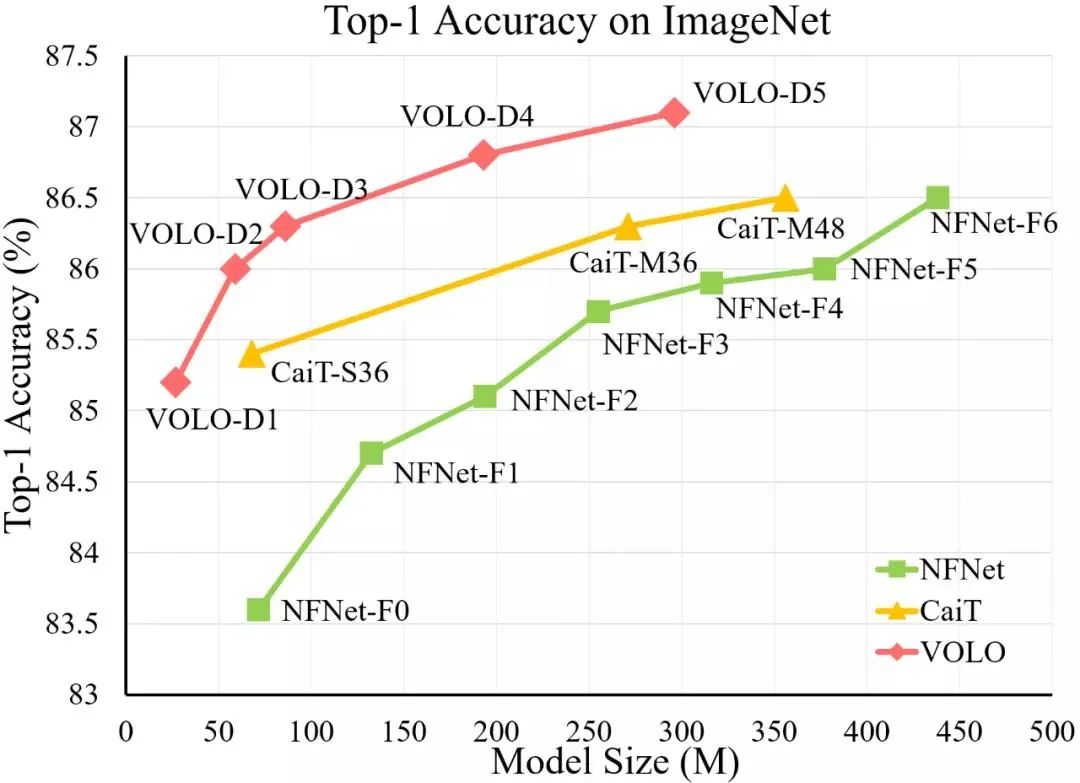
VOLO 模型与 SOTA CNN 模型(NFNet)和 Transformer 模型(CaiT)的 ImageNet top-1 准确率比较。在使用更少参数的情况下,VOLO-D5 优于 CaiT-M48 和 NFNet-F6,并首次在不使用额外训练数据时达到了 87% 以上的 top-1 准确率。
推荐:
无需额外数据,首次实现 ImageNet 87.1% 精度。
论文 3:Strong quantum computational advantage using a superconducting quantum processor
摘要:
在该研究中,研究者表示使用祖冲之号超导量子计算系统中的 56 个量子比特,实现了比当年 Google Sycamore 处理器 53 个量子比特强 2 至 3 个数量级的量子优越性。文章指出,「祖冲之号」将现存功能最强大的超级计算机需 8 年完成的任务样本压缩至最短 1.2 小时完成,从而证明了量子计算的巨大优越性。不论是从量子比特数目、保真度,还是在 T1 寿命等指标上,祖冲之号的超导量子计算系统都实现了国内领先,全球前三的水平。
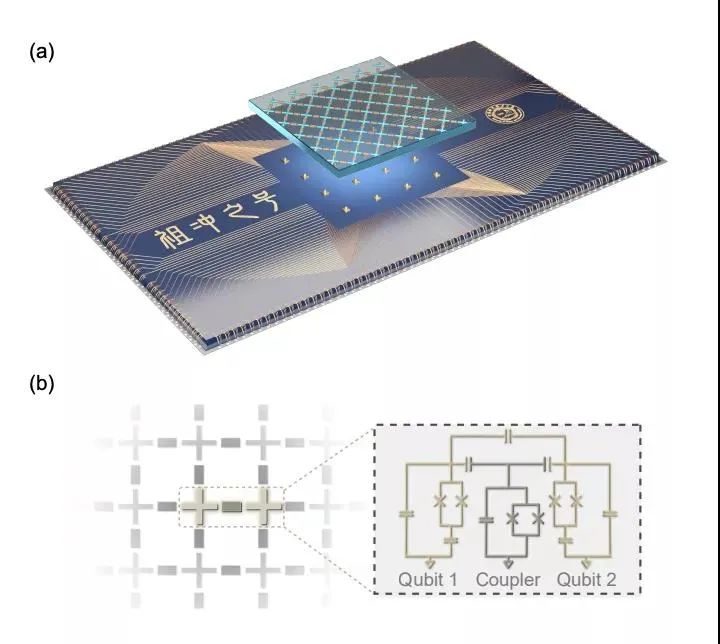
从论文中,我们可以看到潘建伟团队实现量子优越性的关键数据。下图为祖冲之号量子处理器示意图。如图(a),该处理器由两块蓝宝石芯片组成,一块载有 66 个量子比特和 110 个耦合器,每个量子比特都与相邻的四个量子比特相接,处于边界处的量子比特除外;另一块载有读出器和控制线及布线。这两块芯片与铟柱直线对齐并且边界相连。图(b)是量子比特个耦合器的简化电路图。
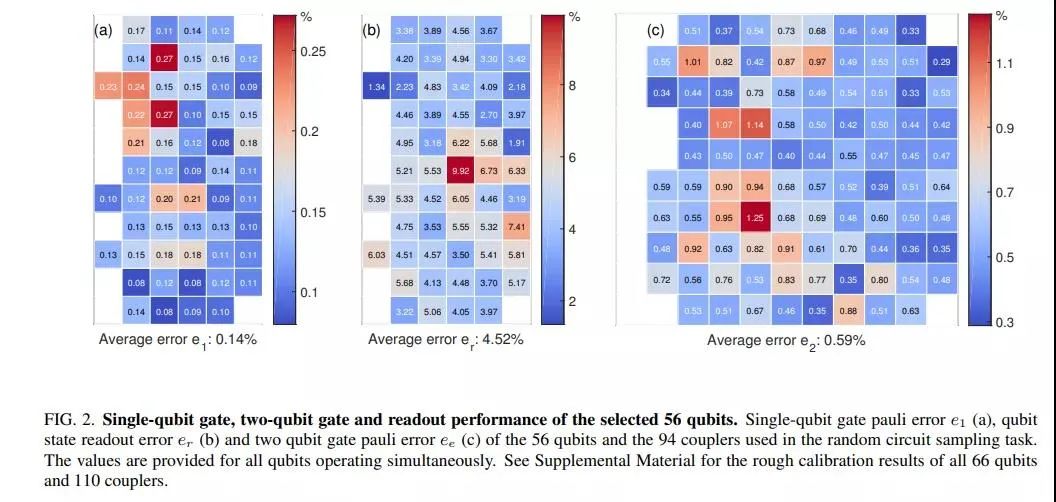
研究者选取了其中的 56 个量子比特来展示随机电路采样,这些量子比特经过优化以实现经典模拟中的最佳计算复杂度。下图 2 展示了单量子比特门、双量子比特门和选取的 56 个量子比特的读出性能(readout performance)。
推荐:
56 比特!潘建伟团队「祖冲之号」展示量子计算优越性,超越谷歌。
论文 4:Deep Learning for AI
作者:Yoshua Bengio, Yann LeCun, Geoffrey Hinton
论文链接:https://www.nature.com/articles/nature14539
摘要:
图灵奖获得者、深度学习三巨头 Yoshua Bengio、Yann LeCun、Geoffrey Hinton 再次联手,在 ACM Communication 上发表文章《Deep Learning for AI》,回顾了近年来深度学习的基本概念和一些突破性成就,描述深度学习的起源,以及讨论一些未来的挑战。
人工神经网络的研究源于以下观察:人类智能来自于高度并行的、相对简单的非线性神经元网络,这些神经元通过调整其连接的强度来学习知识。这一观察引发出一个核心计算问题:这种一般类型的网络如何学习识别物体或理解语言等困难任务所需的复杂内部表示呢?深度学习试图通过深度表征向量和最优化损失函数得到的权重链接来回答这个问题。非常令人惊讶的是,这种概念上简单的方法在使用大量计算资源和大型训练集时被实验证明是如此有效,而且似乎一个关键因素是深度,即浅层网络无法正常工作。本文将回顾近年来深度学习的基本概念和一些突破性成就,描述深度学习的起源,以及讨论一些未来的挑战。这些挑战包括在很少或没有外部监督的情况下进行学习,处理来自与训练样本不同分布的测试样本,以及使用深度学习方法,用于那些人类通过一系列步骤有意识地解决的任务 —— 即 Kahneman 称之为 system 2 而非 system 1 的任务,例如对象识别或即时自然语言理解。system 1 的任务往往更轻松。
推荐:
Yoshua Bengio、Yann LeCun、Geoffrey Hinton 再次联手,发布万字长文。
论文 5:Scaling Vision Transformers
摘要:
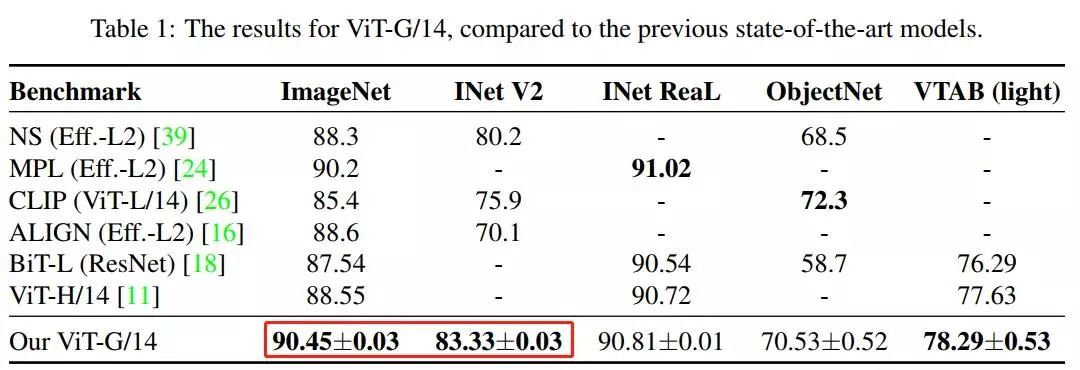
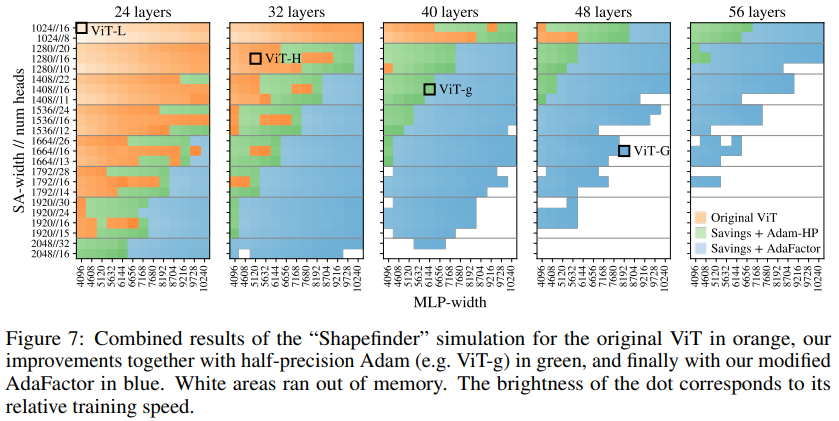
基于注意力的神经网络,如视觉 Transformer(ViT)最近在许多计算机视觉基准上取得了最先进的成果。Scale 是获得优秀结果的主要因素,因此,了解模型的 Scale 特性是有效设计特征形成的关键。同时,人们也研究了变换语言模型的伸缩规律。视觉变形器的规模是未知的。为了解决这个问题,我们对 ViT 模型和数据进行了向上和向下的扩展,并描述了错误率、数据和计算之间的关系。在此过程中,来自谷歌的研究者改进了 ViT 的体系结构和训练,减少了内存消耗并提高了结果模型的准确性。结果训练了一个具有 20 亿个参数的 ViT 模型,该模型在 ImageNet 上获得了最高准确率——90.45%,此前的 ViT 取得的最高准确率记录是 88.36%。
ViT-G/14 型号基于 Google 最新的 Vision Transformers 开发 (ViT)。在包括 ImageNet、ImageNet-v2 和 VTAB-1k 在内的众多基准测试中,ViT-G/14 击败了先前最先进的系统。
论文 6:CoAtNet: Marrying Convolution and Attention for All Data Sizes
摘要:
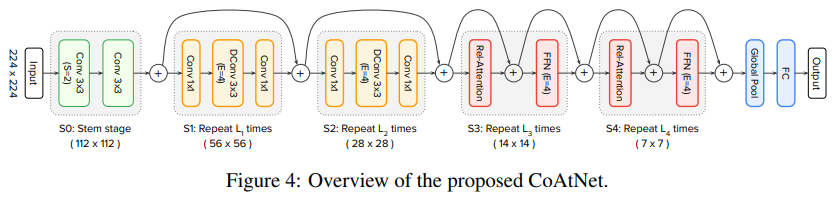
Transformer 在 CV 领域取得了非常好的性能,在有额外数据(例如 JFT)用于预训练的情况下,视觉 Transformer 的结构更是能够超过了 CNN 的 SOTA 性能。但是在只使用 ImageNet 的情况下,ViT 结构的性能距离 CNN 还是有一定的差距的。这可能是由于 Transformer 没有像 CNN 那样强的归纳偏置(inductive bias),因此,来自谷歌的研究者提出了 CoAtNet(Co nvlutio+At tention)将卷积层和注意层相结合起来,使得模型具有更强的学习能力和泛化能力。
在卷积的选择上,研究者采用的是 MBConv。简单来讲,MBConv 有两个特点:1)采用了 Depthwise Convlution,因此相比于传统卷积,Depthwise Conv 的参数能够大大减少;2)采用了「倒瓶颈」的结构,也就是说在卷积过程中,特征经历了升维和降维两个步骤,提高了模型的学习能力。
推荐:
谷歌卷积 + 注意力新模型:CoAtNet,准确率高达 89.77%
论文 7:Early Convolutions Help Transformers See Better
摘要:
ViT 的优化非常困难,不仅需要精确的学习率和权值衰减,还需要使用 AdamW 优化器,并且收敛速度慢。其中最近的 MoCov3 中提到 ViT 架构会导致训练过程中出现衰退现象。
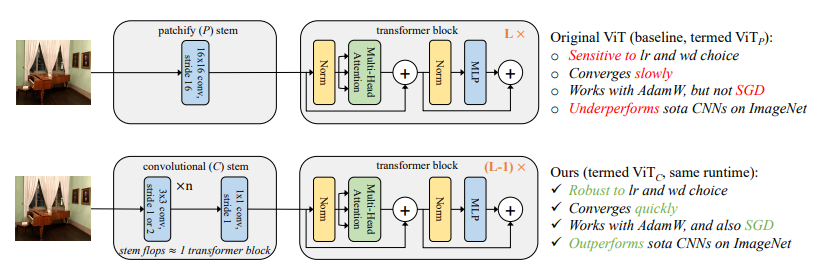
MoCov3 通过绘制第一层和后一层的梯度范数,发现第一层的尖峰出现的比后一层更早,从而推测出 patch projection 是产生衰退的关键,于是通过固定住 patch projection 的参数,缓解了衰退现象。相比之前 hybrid CNN/ViT 的研究,本文的重点是探究 ViT 优化不稳定的本质原因,convoluational stem 替换 patchify stem 对于 ViT 优化稳定性的影响。
本文发现,用 convoluational stem 替换 patchify stem 后,大约使用 5 个卷积就可以在 SGD 优化器上优化,精度不会大幅度下降,并且对于学习率和权值衰减参数不敏感,训练的收敛速度更快。另外,在模型复杂性 (1G 到 36G) 和数据集规模 (ImageNet-1k 到 ImageNet-21k) 的大范围内,ImageNet 的 top-1 精度可以持续提升。

推荐:
卷积可以让视觉 Transformer 性能更强。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
本周 10 篇 NLP 精选论文是:
1. Word2Box: Learning Word Representation Using Box Embeddings. (from Andrew McCallum)
2. Time-Aware Language Models as Temporal Knowledge Bases. (from William W. Cohen)
3. News Article Retrieval in Context for Event-centric Narrative Creation. (from Maarten de Rijke)
4. Learning to Ask Conversational Questions by Optimizing Levenshtein Distance. (from Maarten de Rijke)
5. On the Power of Saturated Transformers: A View from Circuit Complexity. (from Noah A. Smith)
6. All That's 'Human' Is Not Gold: Evaluating Human Evaluation of Generated Text. (from Noah A. Smith)
7. Improving Factual Consistency of Abstractive Summarization on Customer Feedback. (from Yang Liu)
8. Language Models are Good Translators. (from Yang Liu)
9. A Training-free and Reference-free Summarization Evaluation Metric via Centrality-weighted Relevance and Self-referenced Redundancy. (from Irwin King)
10. Representation based meta-learning for few-shot spoken intent recognition. (from Brian Kingsbury)
本周 10 篇 CV 精选论文是:
1. AutoNovel: Automatically Discovering and Learning Novel Visual Categories. (from Andrea Vedaldi, Andrew Zisserman)
2. Attention Bottlenecks for Multimodal Fusion. (from Cordelia Schmid)
3. CLIP-It! Language-Guided Video Summarization. (from Trevor Darrell)
4. On the Robustness of Pretraining and Self-Supervision for a Deep Learning-based Analysis of Diabetic Retinopathy. (from Klaus-Robert Müller)
5. Multimodal Few-Shot Learning with Frozen Language Models. (from Oriol Vinyals)
6. VAT-Mart: Learning Visual Action Trajectory Proposals for Manipulating 3D ARTiculated Objects. (from Leonidas Guibas)
7. O2O-Afford: Annotation-Free Large-Scale Object-Object Affordance Learning. (from Hao Su, Leonidas Guibas)
8. RICE: Refining Instance Masks in Cluttered Environments with Graph Neural Networks. (from Dieter Fox)
9. Single Image Texture Translation for Data Augmentation. (from Tsung-Yi Lin, Serge Belongie)
10. Text Prior Guided Scene Text Image Super-resolution. (from Lei Zhang)
本周 10 篇 ML 精选论文是:
1. Habitat 2.0: Training Home Assistants to Rearrange their Habitat. (from Vladlen Koltun, Jitendra Malik)
2. Accelerating Recurrent Neural Networks for Gravitational Wave Experiments. (from Maurizio Pierini)
3. Generalization and Robustness Implications in Object-Centric Learning. (from Bernhard Schölkopf)
4. Interventional Assays for the Latent Space of Autoencoders. (from Bernhard Schölkopf)
5. Goal-Conditioned Reinforcement Learning with Imagined Subgoals. (from Cordelia Schmid, Ivan Laptev)
6. Compositional Reinforcement Learning from Logical Specifications. (from Rajeev Alur)
7. Modularity in Reinforcement Learning via Algorithmic Independence in Credit Assignment. (from Sergey Levine, Thomas L. Griffiths)
8. Closed-form Continuous-Depth Models. (from Daniela Rus)
9. Multiagent Deep Reinforcement Learning: Challenges and Directions Towards Human-Like Approaches. (from Thomas Bäck)
10. Analytic Insights into Structure and Rank of Neural Network Hessian Maps. (from Thomas Hofmann)
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com


 个人中心
个人中心
 我是园区
我是园区
 退出
退出






