

 个人中心
个人中心
 我是园区
我是园区
 退出
退出
您还不是认证园区!
赶快前去认证园区吧!
创新药物研发从实验室到推向市场需要大量的时间和财力投入,尤其是在药物开发过程中,需要系统研究候选药物的关键生物活性,例如功效,药代动力学(Pharmacokinetics, PK)和不良反应等。随着近十年来化学合成和生物筛选技术的发展,药物研发领域产生了数百万个小分子的生物学数据,并已归纳在各种数据库中。如能发现这些积累的数据与诸如深度学习之类的新机器学习(Machine Learning, ML)方法的合理结合方式,将会对药物研带来巨大的推动力,帮助深入理解化合物结构,预测体外,体内和临床效应,从而促进大数据时代的药物的发现和开发。
药物研发大数据
与社会网络分析等IT领域的应用相比,用于药物发现研究的数据集相对较小。当前与药物发现和开发有关的公开可用数据,根据其在药物发现和开发不同阶段的应用和相关性,可分为六类:(1)全面的化合物数据库(例如,Enamine REAL数据库,PubChem和ChEMBL);(2)专为药物/类药物化合物设计的化学数据库(例如,DrugBank ,AICD 和e-Drug3D );(3)收集药物靶标,包括基因组学和蛋白质组学数据(例如ASD,BindingDB,Supertarget和Ligand Expo);(4)存储通过筛选,代谢和功效研究获得的生物学数据数据库(例如HMDB,TTD,WOMBAT和PKPB_DB);(5)药物安全和毒性数据库(例如,DrugMatrix,SIDER和LTKB基准数据集);(6)临床数据库(例如ClinicalTrials.gov ,PharmaGKB和EORTC临床试验数据库)。尽管这些数据库的数量和规模近年来已大大扩展,但其中很大一部分数据并不是关于药物的发现和开发。
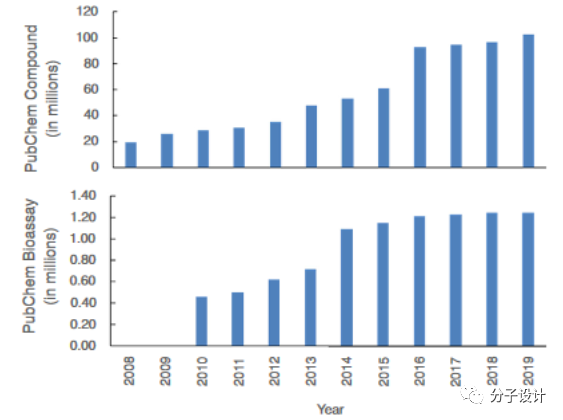
例如,PubChem是化学结构及其生物学特性的公共存储库。PubChem化合物的数量从2008年的1900万增加到2019年的> 9600万,包括大多数药物和候选药物和靶标信息。ASD是专注于变构靶标及其调控化合物的数据库,收集超过20万条已确认的变构证据和超过10万个变构小分子。BindingDB是可通过Web访问的药物靶标结合数据的公共资源,包括测得的结合亲和力数据,靶标蛋白的信息。BindingDB当前包含1756093个针对7371个蛋白质靶标和780240个小分子的结合数据。HMDB(人体代谢物数据库)包含有关人体中发现的小分子代谢物的详细信息,目前包含114162种代谢物,包括水溶性和脂溶性代谢物。DrugMatrix重点研究了600种药物的毒理学数据,包含药物治疗下的大规模大鼠基因表达数据。PharmGKB是涵盖药物分子临床信息的药物基因组学知识资源,包含733种具有相应临床信息的药物。
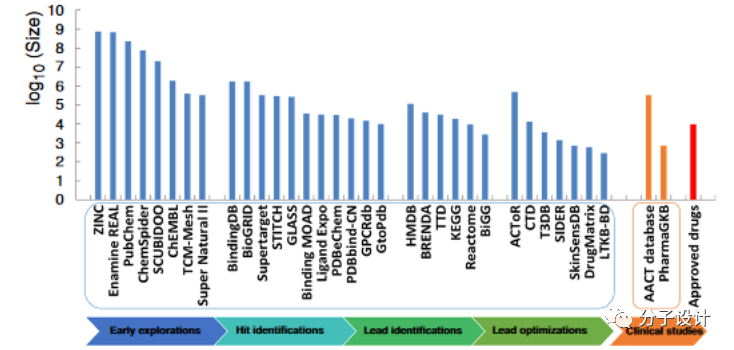
药物大数据的特征
如前所述,大数据驱动的药物研究仍面临长期挑战。在长期开发过程中累积的大量数据,由于是从不同的来源获取的,数据呈现生物条件多样性,虽然这样的数据能给带来一定的信息,但依然要要特别注意以下问题:
首当其冲的是数据质量。随着新型测试技术的发展,药物发现数据的增长已经超出了我们使用它们的能力。然而,缺乏质量控制一直是公共数据库的普遍问题。众所周知,算法建模的研究都会遵循着“垃圾进,垃圾出”的基本原则,因此强调质量控制的重要性,特别是数据真实性和权威性尤为重要。例如,许多报道中检测同一化合物的条件不同,造成该化合物在同一性质上的大量不同数据,这些数据之间甚至互相矛盾。因此,从大数据中率先提炼有意义的数据进行整理是非常必要的。
其次,关键特征数据的缺乏。在采用大数据和ML建立模型助推药物研发时,往往要面临多类数据不足甚至缺乏的局面。如何采取一些步骤来应对这样的问题更加合理是当前数据杂而不全现状下必须要解决的一大困境。比如,可以针对单一靶标建立QSAR模型来外推补足数据;还可以利用“Read-across”方法,即选择已经检测过的分子中和目标分子类似的分子对应的数据来补足数据。但是,无论采用哪种方法都会引入预测误差,尤其是考虑到数据的不同来源,不同的标准化流程,质量控制,专家标注都会使得这个误差问题越发凸显。
另外,计算能力的进步和生物数据量的增长刺激了诸如深度学习等新型ML技术在药物研发中的应用,以应对药物发现大数据带来的多重挑战。深度学习被运用于多个药物发现的任务,比如从头设计,小分子蛋白结合等。在从头设计中,深度神经网络,循环神经网络,生成对抗网络等都已经得到了初步的运用。随着深度学习在异源数据中的作用不断强化,许多研究都提示在其在评价小分子和蛋白结合的模型预测上上,深度学习比普通机器学习更具有优势。然而,药物数据体量和图像识别,棋类游戏,化学反应等应用场景相比仍有极大差距,深度学习类方法在药物研发中应用所面临的最大困境依然是数据严重不足和质量难以统一带来模型过拟合问题。
综上,药物研发大数据和深度学习等人工智能方法已经在药物研发的多个阶段展现了其在创新和加速进程方面的优势,随着数据质量和基于药物知识的人工智能方法发展,我们仍对人工智能方法开辟药物研发新赛道并改变现有传统药物研发模式抱有乐观期待。
参考文献
1. Schneider, G. (2018) Automating drug discovery. Nat. Rev. Drug Discov. 17, 97–113
2. Carney, E.F. (2020) Pharmacokinetic modelling using linked organ chips. Nat. Rev. Nephrol. 16, 188–188
3. Zhu, H. (2019) Big data and artificial intelligence modeling for drug discovery. Annu. Rev. Pharm. Toxicol. 60, 573–589
4. Linlin Zhao, et al. (2020) Advancing computer-aided drug discovery (CADD) by big data and data-driven machine learning modeling. Drug Discovery Today, doi:10.1016/j.drudis.2020.07.005
识别微信二维码,添加生物制品圈小编,符合条件者即可加入生物制品微信群!
请注明:姓名+研究方向!


本公众号所有转载文章系出于传递更多信息之目的,且明确注明来源和作者,不希望被转载的媒体或个人可与我们联系(cbplib@163.com),我们将立即进行删除处理。所有文章仅代表作者观点,不代表本站立场。







