随着技术的进步与升级,无论是深度学习还是边缘计算,对高算力、灵活、稳定、安全等方面都提出了刚需的要求。
复杂多变的部署环境对计算性能的要求愈加严苛,这就要求算力基础设施具备更高的可靠性,以保证长效运行不停机。当普通的算力无法满足当下各领域的需求 ,“新势力” 产品的爆发便成为必然。
数据科学工作站的 “强劲性能” 可以满足对计算性能要求最为严苛的行业需求,尤其是在已经广泛应用 AI 的安防、文娱、医疗、零售、汽车等领域。而实现重要成果的研发、技术不断迭代的背后,首先要拥有高算力、高性能的平台及系列科学数据产品。
通过把脉前沿科技和趋势,洞察用户需求,惠普打造了包含数据采集工作站、微型工作站、Z8 Multi-GPU 工作站、VR 可穿戴设备、以及 Data Science Stack 在内的「Z 系列」革命性产品。
为支持 AI 领域研究,共同推动中国 AI 领域的原始创新,拓展认知新边界,惠普数据科学工作站联合 DeepTech 深科技共同发起了“惠普人工智能合作伙伴招募计划”。
基于惠普在数据科学系列产品的多样性和专业性,为 AI 领域的企业、科研人员提供高算力、高性能的硬件产品测试,共同制定未来的产品解决方案。
那么,惠普多形态的产品是否可满足不同企业、不同场景的运算需求?一体化的解决方案是否在实际应用场景中助力实现行业的突破与创新?
我们在“惠普人工智能合作伙伴招募计划”第一期的企业中筛选了四个典型案例。他们经过 1-3 个月的使用,对 HP Z8G4 数据科学工作站进行了测评,产品的应用场景分别为自动驾驶的感知、算法训练,NLP 大模型训练,硅光芯片的设计、模拟和仿真,生物计算分子模拟平台的训练、算法演进等,以下为各企业实际测评。
毫末智行

使用场景:自动驾驶的感知、算法训练
机器型号:HP Z8G4 数据科学工作站
CPU:2*Intel Xeon Silver 5218R 2.3Ghz 16C 125W
GPU:2* NVIDIA RTX 8000 48G
GPU 使用场景
1.无监督对比训练、MoCo 算法训练
通过图像增强训练对比学习效果,模型大小 277M、训练数据 100W,最终输出特征纬度为 256 维浮点数。训练图像的分辨率为96*96、采用两块 GPU 训练、Batch_Size(批尺寸)大小为 512、iteration(迭代)一次 200 秒。

图丨训练数据(来源:毫末智行)
2.自动驾驶时序目标检测
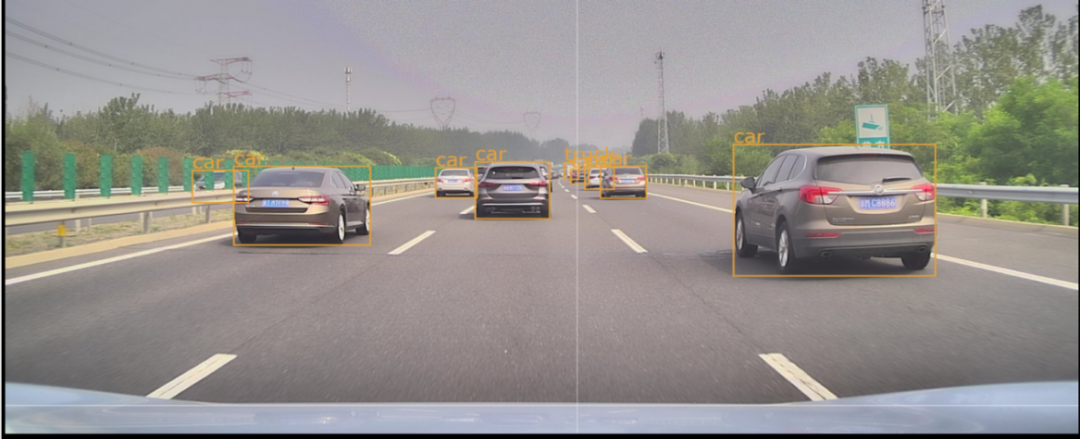
图丨训练样本示例(来源:毫末智行)
采用 YOLO 系类模型对自动驾驶路面的障碍物进行识别,40W 数据、2 块 GPU 训练,训练样本分辨率为 1280*720,每个 Batch_Size 可以输入 16 张图片,迭代一次 2 秒。
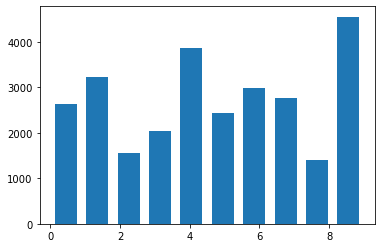
图像的聚类分析,通过 k 均值聚类算法(k-means clustering algorithm),聚类数据大小 2.7w、聚类数量 10 类、耗时 7 秒。
图丨图像聚类分析按类别的数量结果(来源:毫末智行)
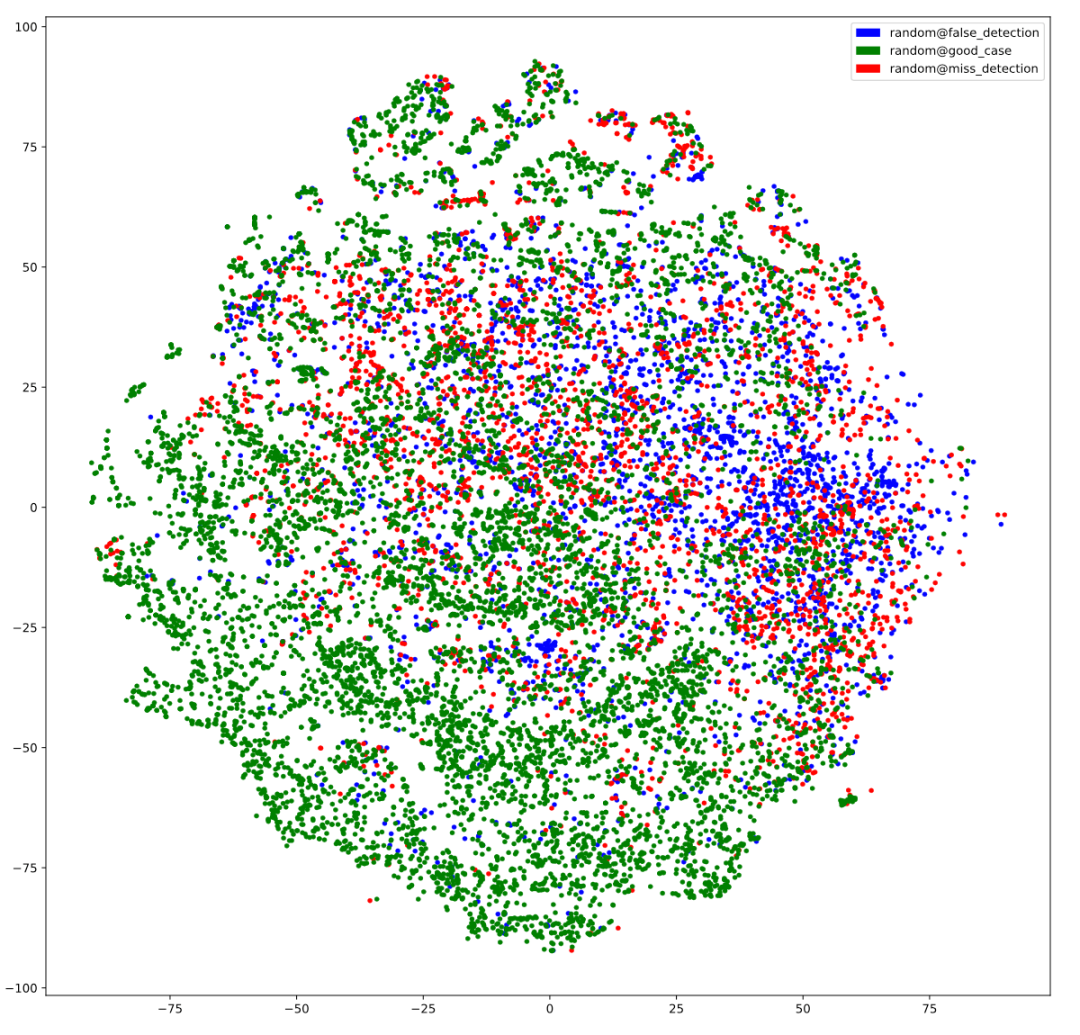
图丨用 TSNE 可视化数据结果(来源:毫末智行)
其他效果:机器运行噪音小,整体开关机速度流畅,体验良好。
CPU:2*Intel Xeon Silver 4210R 2.4Ghz 12C 100W
GPU:2* NVIDIA RTX A5000 24G
在需要使用 GPU 的场景,以训练景甜和薇娅换脸模型 SAEHD 为案例:
1.使用到 GPU 的地方第一个是进行图片脸部检测,即需要对视频分割出的每一帧来判断图像中是否存在人脸,这一步使用的是 S3FD 模型,需要大规模的 GPU 运算;
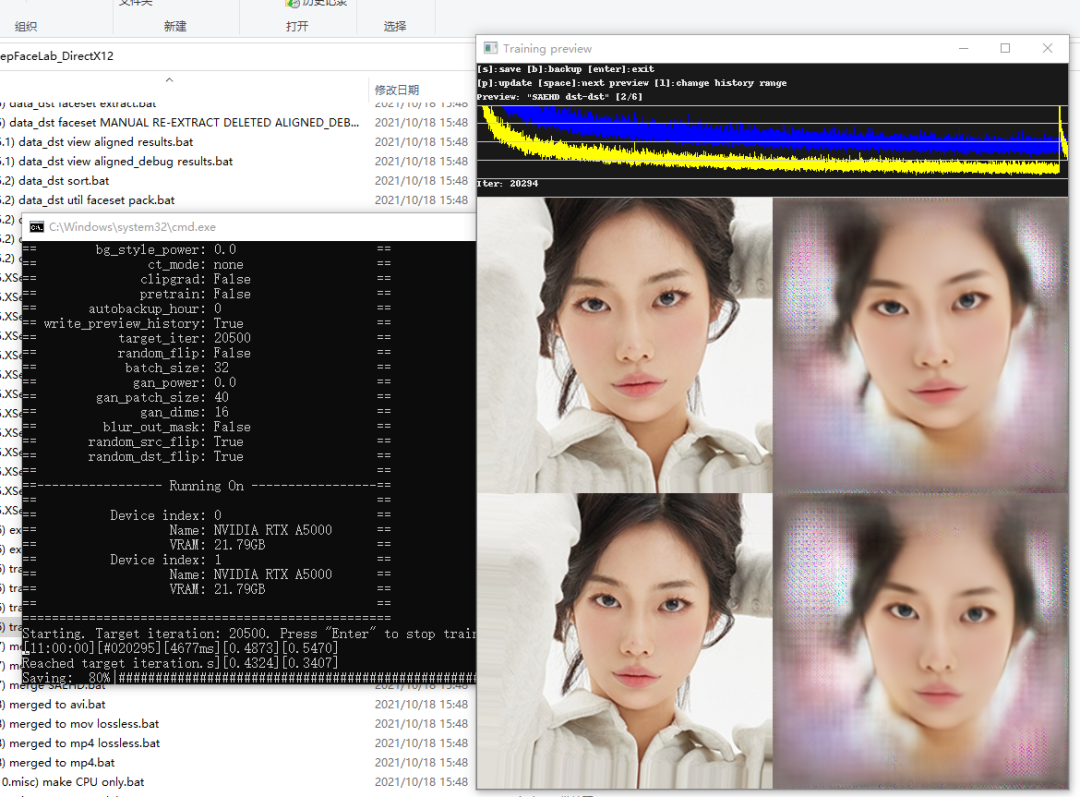
图丨训练网络时 loss 损失下降和对应的预览图(来源:循环智能)
2.另外一个需要使用到 GPU 的场景是训练换脸模型 SAEHD,模型大小 4.37GB,可以同时使用两块 24G 显存的 GPU 进行训练,Batch_Size 可以开到 32,分辨率设置到 512*512,平均每个 iteration 用时 5 秒左右。
深度换脸技术很多地方需要大量的 CPU 运算,以本项目为例,大量使用 CPU 进行运算的场景如下:
这里是将一段 4 分钟 29 秒的视频进行拆帧,共得到 6466 张图片,总耗时在两分钟内,速度较快。
图丨将视频按照指定的帧率进行拆分成视频帧(来源:循环智能))
可以自定义合成视频的比特率,帧率等参数,然后合成的时候可以选择使用的 CPU 核数。在这里,可以使用到 20 核 40 线程,多线程跑满,速度也比较快。
图丨将处理好的视频帧合成为最后的视频具体使用效果图(来源:循环智能)
1.磁盘空间足够大,3 个 1.8T 的磁盘可以存放很多数据;
CPU:2*Intel Xeon Silver 4210R 2.4Ghz 10C 100W
GPU:4* NVIDIA RTX A4000 16G
使用 Vivado 设计套件进行 FPGA 的综合实现
Vivado 主要使用 CPU 和内存资源,所以,本次测试并没有使用强大的 GPU 资源。而是对 CPU 多核心和内存的使用情况做了使用分析。
·执行 implementation 线程数都设置为 8
片上资源使用情况:片上资源使用率较高,如 RAM 基本全部用掉。
第一,单个 Design Run,121min 左右完成,资源管理器显示使用 8 个逻辑线程,其余空闲;
第二,2 个同样的 Design Run,分别使用 119min 和 125min 左右完成,资源管理器显示使用的是 16 个逻辑线程,其余空闲,但是在运行中间线程会切换;
第三,3 个同样的 Design Run,分别使用 136min、139min 和 150min 左右完成,资源管理器显示使用的是 24 个逻辑线程,其余空闲,但是在运行中间线程会切换;
第四,6 个同样的 Design Run,分别使用 140min、142min、150min、159min、160 和 160min 左右完成,资源管理器显示使用的所有线程基本都处于工作态。
1. CPU 多核心使用起来确实很快,对于 CPU 和内存资源有刚需的场景下有很大的挖掘潜力,相信对于 GCC 编译大工程会有巨大的效率提升;
2. 对于同时运行多 implementation 任务,有很大吸引力;
3.Vivado 使用 eclips 框架+插件的方式速度相对较慢、可优化余地较大,但是稳定性较好。
其他使用体验
1.外形:机器净重 20.9 公斤,外形稳重,用料踏实,质感很好;
CPU:2*Intel Xeon Silver 6230R 2.1Ghz 26C 150W
GPU:2*NVIDIA RTX A6000 48G
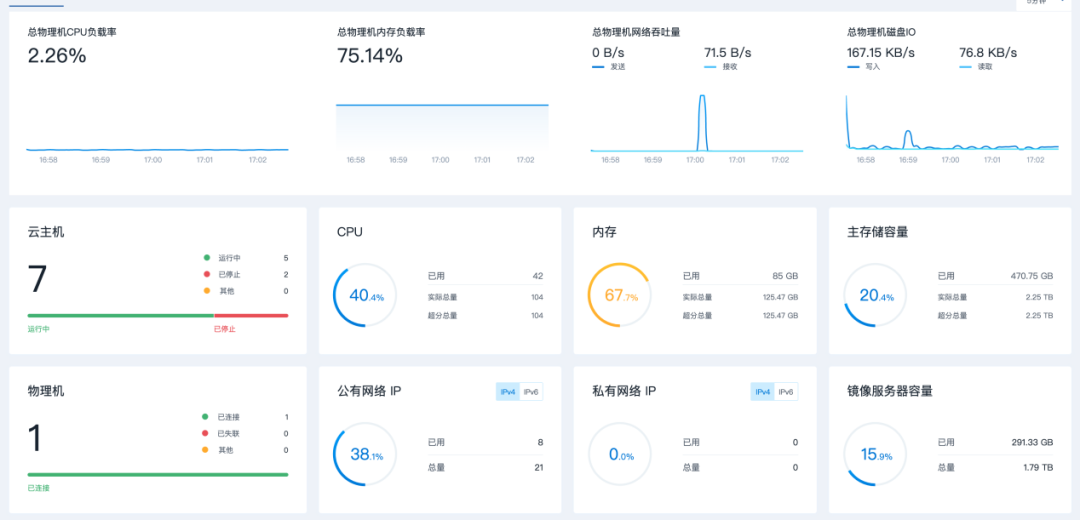
虚拟化平台部署
采用 ZStack3.10.13 虚拟化套件对工作站资源进行虚拟化。使用虚拟化技术后,可大幅提高可用服务器数量以及服务器资源的利用率。
单台工作站可提供 104vCPU 及 125GB 内存。由于工作站选择了一块 GPU 作为主显卡,虚拟化后仅可提供一块 GPU 供虚拟机使用。
应用管理平台部署
采用 k8sv1.20.4 容器管理平台对应用系统进行管理,便于应用持续开发、集成和部署。提供可靠和频繁的容器镜像构建和部署,并提供快速和轻松的回滚。
高性能计算平台部署
采用 slurm-21.08.0 作为高性能计算资源调度平台,提供高度可伸缩和容错的集群管理器和作业调度系统,被世界范围内的超级计算机和计算集群广泛采用。
SLURM 维护着一个待处理工作的队列并管理此工作的整体资源利用。它以一种共享或非共享的方式管理可用的计算节点(取决于资源的需求),以供用户执行工作。SLURM 会为任务队列合理地分配资源,并监视作业至其完成。
科学计算数据结果
· GPU Driver Version: 470.74
AlphaFold标准尺寸的训练效率17.5s/step
prediction and complie time
总体来看,参与本次测评的「Z 系列」产品可不同程度地满足不同应用场景下的专业性需求,使用测试样机后,部分性能较传统产品有显著改善。对于机器运行各企业普遍认为噪音小、机器运行状态良好。部分性能还在测评中,对于产品部分细节方面有待进一步优化。


 个人中心
个人中心
 我是园区
我是园区
 退出
退出